ML/Research · Dec 2024 to Present
Fusion Plasma Four-State Classification
Deep learning and sequence models that read four distinct plasma behaviors (Suppressed, Mitigated, ELMing, Dithering) out of fusion-reactor sensor data at Columbia Fusion Research Center.

Problem statement
A tokamak is a donut-shaped fusion reactor that uses powerful magnets to trap superheated gas (plasma) at roughly 100 million degrees, hot enough for hydrogen nuclei to fuse. The big operational headache is a recurring instability called an edge-localized mode, or ELM: the outer edge of the plasma periodically "burps," dumping heat and particles onto the reactor wall like a pressure valve firing too hard. Left unchecked, ELMs erode the wall and shorten reactor lifetime.
The fix is to apply tiny, carefully shaped magnetic ripples called resonant magnetic perturbations (RMPs) that act as a slow pressure-release for the edge, preventing the big burps. The catch: if the ripples are too strong they wreck the plasma entirely, and if too weak the ELMs come back. Operators need to land inside a narrow window.
Before anyone can study that window, every millisecond of every experiment has to be labeled with which of four behaviors the plasma is in:
- Suppressed: no ELM bursts, the calm state engineers actually want
- Mitigated: smaller, less frequent bursts; partial control
- ELMing: frequent, full-sized bursts; the problem state
- Dithering: mostly calm but with an occasional burst every 50 to 200 ms, meaning the plasma is sitting right on the knife-edge between suppressed and unsuppressed
The labels come from a light-sensor on the reactor called filterscope FS04 that detects a specific red glow (the Dα line) emitted whenever hot particles strike the wall during an ELM. Each state has a distinct fingerprint in that signal, which is what the ML model learns to read.
My role and contributions
I own the end-to-end ML side of the pipeline at Columbia Fusion Research Center: manually labeling experimental runs ("shots") against the FS04 light sensor and other plasma diagnostics, building out the features, designing and training the models, and honestly evaluating them on held-out shots the model has never seen.
I grew the hand-labeled dataset from 36 shots / ~5,800 one-millisecond data points to 88 shots / ~200,000 data points. I then used a smaller model trained on that manual set to auto-label thousands more shots from DIII-D (the national tokamak user facility in San Diego), producing a multi-million-point training set while keeping the manually labeled shots as a permanent test set the models never get to train on.
In Summer 2025 I extended the stack to temporal convolutional networks (TCNs) and long short-term memory networks (LSTMs) that could chew through those bigger datasets on GPU. Now I'm working on a forecasting variant: instead of just labeling what the plasma is doing right now, it predicts what it will do 50 to 100 ms from now given the operator's control inputs. The target is a model that can warn an operator "you're about to lose suppression" with enough lead time to actually do something about it, and eventually plug into DIII-D's real-time Plasma Control System.
Technical approach
At its core, this is multi-class sequence classification: given a short window of reactor sensor readings, output which of the four plasma states we're in. The inputs are things like the currents in the RMP coils, the density and pressure at the plasma edge, plasma shape, and the FS04 light-sensor signal itself.
I built two complementary stacks:
- Random Forest baseline (scikit-learn): an ensemble of decision trees. Used as the sanity-check model: it's interpretable (you can ask it "which sensors matter most?") and robust to missing data, which is common in experimental physics. I used forward feature selection (add one feature at a time, keep the one that helps most) and tuned the tree parameters one axis at a time.
- Hybrid CNN-BiLSTM with attention (PyTorch): a deep model built for time series. Two 1D convolutional layers first scan the signal for the fast spike patterns that define ELMs; a two-layer bidirectional LSTM then carries the slower evolution of the plasma pressure over the full window; an attention head learns which moments in the window are most informative; and a small classifier head maps that to the four states. I used focal loss so the model pays extra attention to the rarer dithering and mitigated states instead of getting lazy and always predicting the common ones.
One of the more valuable lessons came from a causal-leakage problem. Because the FS04 light sensor and the plasma density are physically tied to how the states are defined, a naive model can "cheat": it learns to recognize that the plasma is already suppressed instead of predicting whether it will suppress. I addressed that by reframing the problem as forecasting from the operator's control inputs alone (neutral-beam heating power, electron-cyclotron heating, plasma shaping, coil currents, gas fueling) at lookaheads of 0, 1, 10, 50, and 100 ms.
Results
The hybrid CNN-BiLSTM with attention is the model that carries this project. Two confusion matrices show how it stacks up against the Random Forest baseline on the same 88-shot dataset and the same stratified protocol.
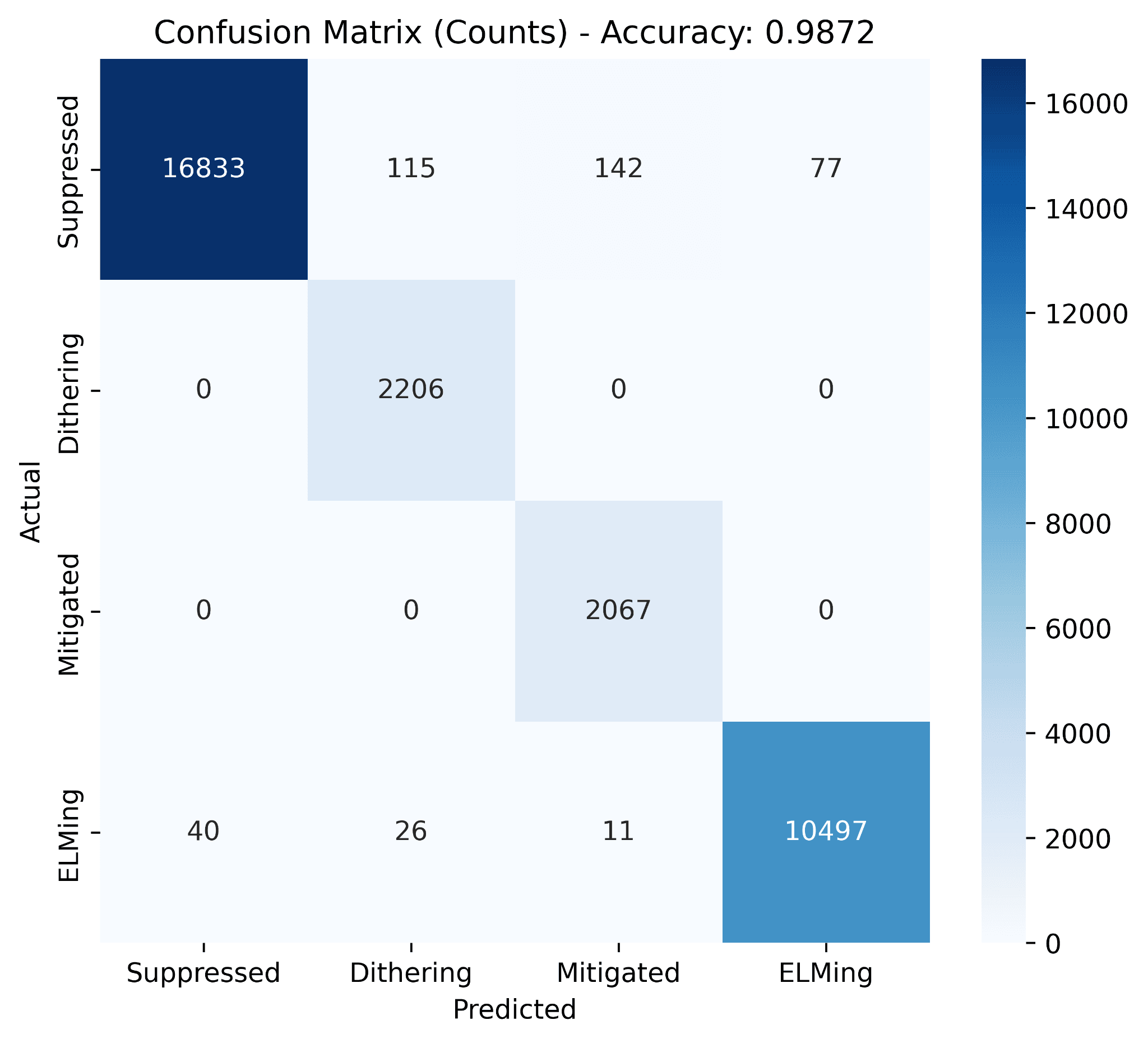
Point-wise split (random across every 1 ms sample from all 88 shots):
Shot-wise split (whole held-out shots the model has never seen):
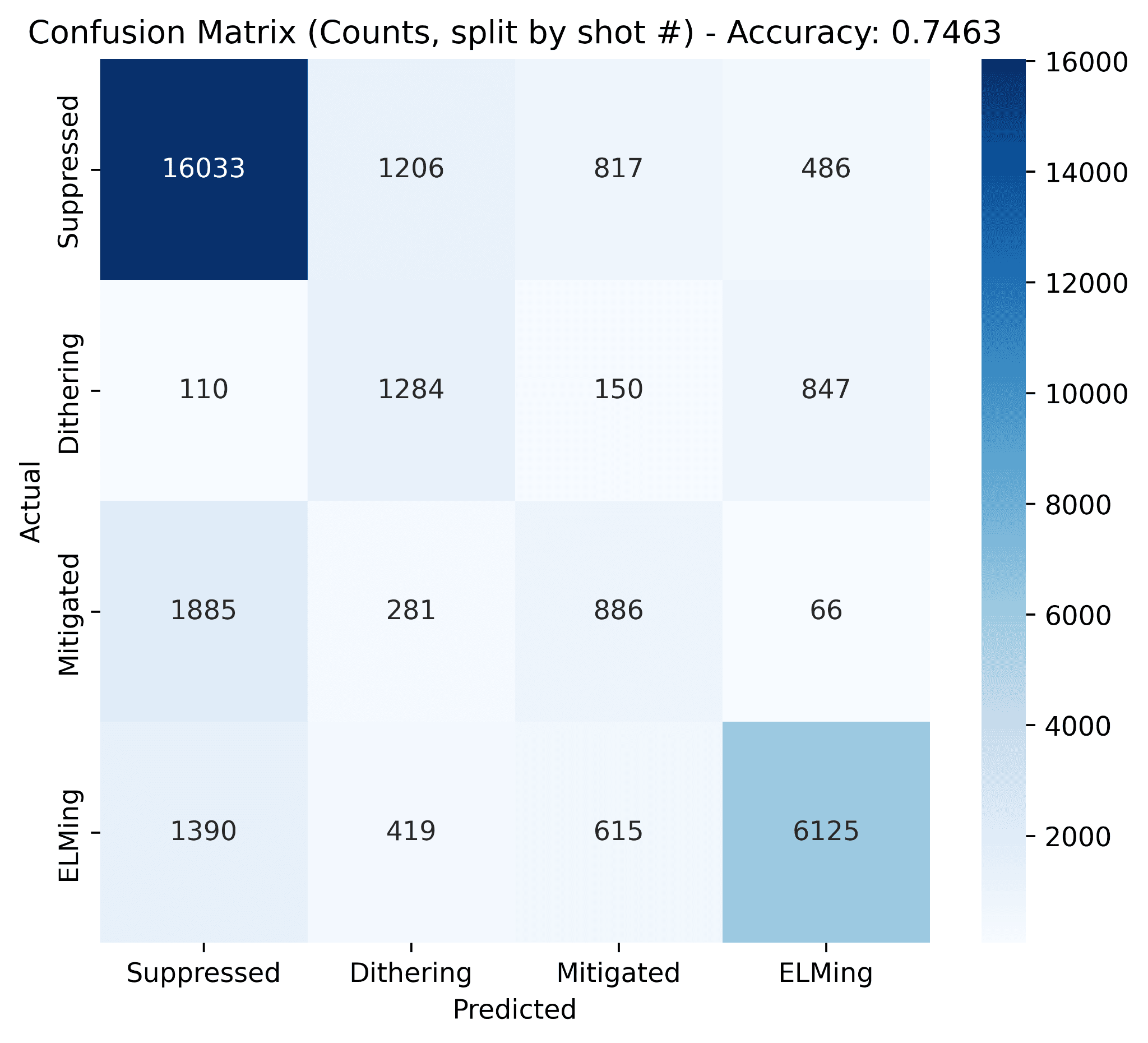
On the point-wise split the hybrid hits 98.7% accuracy, close to the Random Forest's 99.6%. On the shot-wise split, where every point in the test set is from a shot the model has never seen, it reaches 74.6% against the Random Forest's 71.5%. That gap is the value added by modeling temporal context explicitly: the CNN reads the fast ELM spike patterns while the BiLSTM carries the slower pressure evolution across the window, and the attention head weights the moments that actually matter.
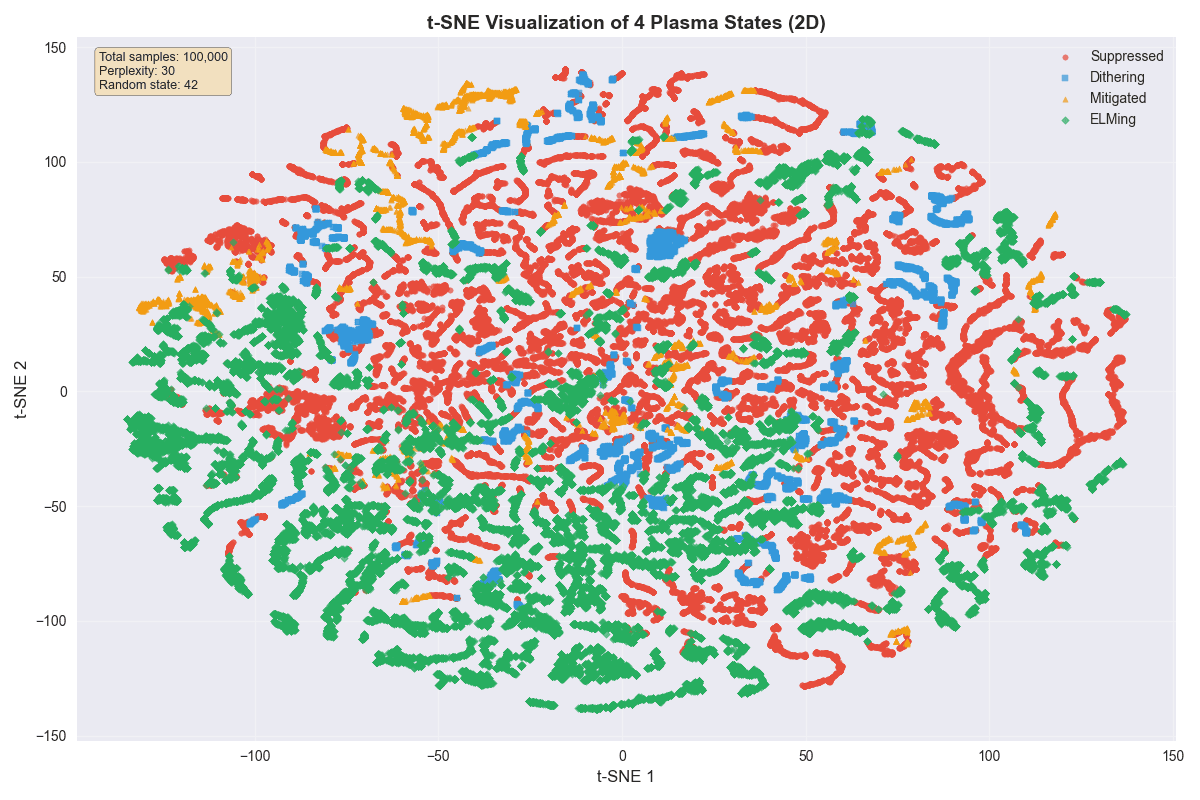
A t-SNE embedding of the four plasma states explains where the residual errors come from:
At larger scale and with different framings:
- Portfolio benchmark: 4-state plasma event classification, achieving 95.6% accuracy on 200K+ data points using PyTorch.
- Summer 2025 scale-up: TCN and LSTM models trained on 7,000,000+ auto-labeled points reached 90.8% accuracy with roughly 88% less runtime by moving training to an A100 GPU instead of CPUs.
- Feature findings line up with the physics: ELMing tends to happen when the plasma current is spread out across the cross-section and the edge density is high (~4.5 × 10¹³ cm⁻³); suppression happens at more peaked current profiles and lower edge density (~3.7 × 10¹³ cm⁻³); dithering, fittingly, spans the widest range of both, which is exactly what you'd expect from a state that sits on the boundary between the other two.
Stack notes
PyTorch, scikit-learn, CUDA (A100 GPU training), Python, NumPy, SciPy, Matplotlib, Optuna for hyperparameter search, and the DIII-D analysis tools (OMFIT and reviewplus) on the iris compute cluster for pulling and hand-labeling experimental data, in collaboration with Columbia Fusion Research Center.
Tech stack
- PyTorch
- CUDA
- time-series ML
- CNN
- BiLSTM
- fusion energy